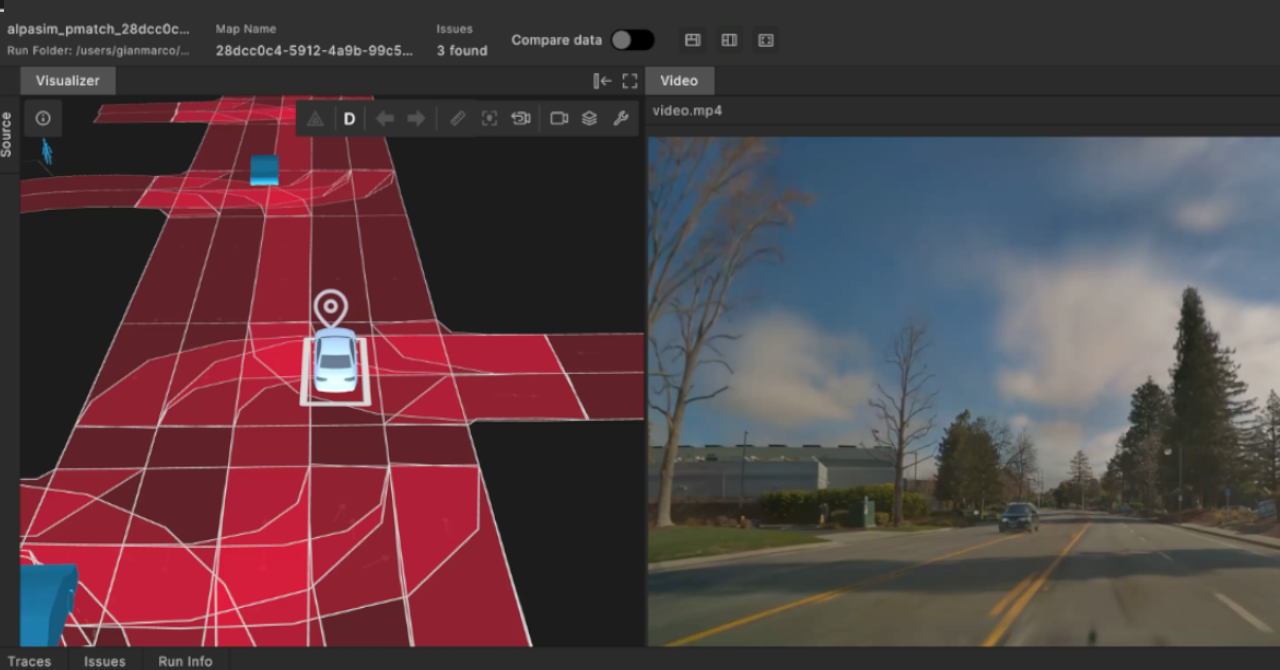
Our first two OSC2 automation expert seminars were extremely successful, with hundreds of attendees and a lively exchange of information both in the Q&A sessions and on chat. We would like to thank all attendees. We hope that this was informative and valuable for you and appreciate the positive feedback that we have received so far. Our goal with these webinars is to visit key topics and jointly find solutions for the benefit of the industry.
Many users requested a transcript of the webinar Q&A segment, and this blog post is dedicated to that. Note that it is more informative than our typical blogs. It ranges from conceptual, methodology, and standard implementation questions, but you can choose to read all of it or jump to the specific answers.
Feel free to bring up other topics of interest in the comments below or send an email to info@foretellix.com. We will do our best to respond to any requests within the next couple of sessions and maybe even hold full sessions around the deeper or more interesting topics.
We have already published the date of our next webinar on the much-requested topic of requirements-based testing and how to efficiently deploy this with an automated V&V process. The webinar will take place on the 24th of March 5pm CET. You can register to join and ask questions.
Questions:
- Is there also the intent to be used to create or validate datasets for machine learning technologies?
- How can a random scenario be generated without defined constraints
- Are the road and intersection an “actor”?
- Are there standards for reporting logs of each run to understand failure states and pre and post-actor states?
- “Lane change” is a good concept in environments that provide lanes. But what about environments with mere “free space traffic” (think of Indian roads with lots of single-track vehicles)?
- How to know the CDV does not have a major hole? How do you know you have done enough to “verify”?
- How do you calculate the coverage metrics?
- How do you handle the issue “curse of dimensionality”. If I have 100 parameters, will the platform test all combinations?
- In your demo showing the test scores, ranks, etc., could you explain again what you are optimizing in terms of “ranks?”
- Can your tool be also used for parameter identification through its optimization capabilities? Is there a predefined workflow for that?
- Do you consider the probability of scenarios when selecting them or when evaluating the performance of the AV in the report?
- How do you define “undesirable” results such as a collision?
- Are these sequences of behaviors open loop? e.g. in the lane overtaking sequence, could you randomly generate a sequence where the actor sideswipes the AV? How would you isolate those scenarios where a collision is due to an overly aggressive actor rather than the AV’s failure? Since you’re generating a huge volume of scenarios, manual triage isn’t an option.
- If the randomly picked parameters generate a combination that is not physically possible for a vehicle at runtime, how is it handled?
- Is there an open parser/interpreter to validate a scenario?
- How should we set the scenario parameter range?
- Are the trajectories generated kinematically feasible by default? If not, is there a way to encode such constraints?
- How do you create edge case scenarios?
- Is there a reference implementation for tools implementing the format?
Is there also the intent to be used to create or validate datasets for machine learning technologies?
Before addressing the question, it is important to clarify that the OpenSCENARIO 2.0 is a standard input format, and the ability to capture scenario intent can fuel multiple tools and purposes. The standard itself neither limits nor dictates a specific purpose, flow, or tool. In regard to training, we agree with the question’s suggested direction. The steerable random flow allows users to create multiple surprising scenarios that can be used for both training and validation purposes. There is much more to be said on the training flow and the mix of surprises with real-life probabilities.
How can a random scenario be generated without defined constraints?
As the question suggests, for a lot of practical applications you need to use constraints. Logical scenarios allow random selection (aka Monte-Carlo) within ranges. These ranges define a space of scenarios to be tested but this isn’t enough for most practical purposes. Attributes such as speed, distance, time, acceleration, and even the road, are tightly correlated with implied physical constraints. For example, driving at a certain speed for a certain amount of time determines the distance traveled and requires a road of sufficient length. Constraints also provide abstraction. They allow capturing a high-level intent in a formal description. This is necessary for technology to replace the tedious cognitive work by humans that is currently the norm. For example, the tool will select a proper segment for a cut-in scenario, adjusting the scenario’s physical and intent considerations accordingly.
Are the road and intersection an “actor”?
Roads and intersections are structs composed of multiple segments. See the domain model subsection in the LRM.
Are there standards for reporting logs of each run to understand failure states and pre and post-actor states?
We agree that this is needed. In general, the more you can standardize the better, but the creation of 2.0 was a huge cooperative effort. One reason this version of OpenSCENARIO is called 2.0, is that we will eventually have more than just two versions. There was a lot of excellent work done to standardize things, yet some solid ideas just couldn’t fit into our schedule for 2.0. For instance, there are basic methods of reporting errors and warnings as well as more sophisticated controls that were postponed to a future release. Foretellix has standards that we will be happy to contribute to subsequent versions, but we’ll see how that pans out.
“Lane change” is a good concept in environments that provide lanes. But what about environments with mere “free space traffic” (think of Indian roads with lots of single-track vehicles)?
The OSC2.0 domain model includes many actions and modifiers in addition to lanes, such as movable objects that can move in free space, and a car that can drive along paths. See the LRM for more details.

How to know the CDV does not have a major hole? How do you know you have done enough to “verify”?
There is no single solution that ensures 100% full coverage of the entire scenario space. Coverage Driven Verification allows you to simply and effectively define and achieve goals. The use of automation enables scale and measurability and reduces room for human errors. As such, it is more effective than the manual approach which often suffers from major holes. At the same time, there are important points to make about CDV and the possibility of missing holes:
- The use of random generation may expose unknown, overlooked conditions. The combination of this and generic KPIs identifies holes in your original plan.
- The abstraction and ability to create reusable V&V packages allow aggregating expertise and interesting scenarios. Over time, your reusable scenarios become a thorough asset to rely on.
- The coverage goals can be automatically or manually extracted from multiple complementary resources and execution platforms. Optimizers can take these as starting points and steer the automatic test creation to visit risky areas.
CDV enables an automated flow full of checks and balances to identify coverage holes or missing requirements.
How do you calculate the coverage metrics?
OSC2.0 coverage features facilitate organizing infinity with a gradable coverage model. As a basis, each coverage item is calculated according to its collected type expressions:
- For Boolean expressions (for example, was the siren on) – both true and false need to be observed for 100% coverage, so observing just one of the values is 50% coverage (one out of two). No observed value means 0% coverage.
- For enumerated types (for example, was the vehicle category truck, sedan, or van), the number of observed values divided by the number of possible values is the verification grade. For example, if an enum type has three possible values and two of these were observed in a test suite, the verification grade is 2/3, or 66 percent.
- For continuous values such as speed, which is an unsigned integer, the user can create buckets of values and count the hits in each bucket. For example, a speed of 0 to 120kph can be split into four buckets: 0..30, 31..60, 61..90, 91..120. By default, one hit in a bucket is sufficient to declare the bucket to be covered.
- The overall average of all the calculated item grades is the overall coverage grade.
OSC2 lets you further shape the grades by ignoring values that are not interesting (for example, I do not care about trucks in my project), setting a different target for some values (for example, I want to try at least 10 cut-ins from the right and 5 are enough from the left), and more. Users may build different dashboards and analytics tools around these language concepts.
How do you handle the issue “curse of dimensionality”. If I have 100 parameters, will the platform test all combinations?
This is the core issue of taming infinity. Scenarios have parameters, each with a certain range of values. Also, because you can always mix scenarios, each with multiple parameters, the possibilities will never end, right? Even thinking about that makes your head spin. And one of the things we try and show — and I think you got at least a first glimpse of it — is that there are ways to use coverage definitions and related technology to make this a kind of optimization problem in the following sense: if you just have one night and, say, a hundred machines, what is the best way to use those resources to collect a first pass coverage?
If you have a weekend and a thousand machines, then here is your next step, but you’re going to cover all your scenarios, breadth-first at least to some degree. Then if you have more time, you can collect more and more coverage. And obviously, you will never do all the combinations. In fact, even with just a single speed parameter, you will never get to all the combinations. So technology and methodology are required to make a practical solution.
So as I think the writer of this question already implied, when you define your coverage, you should be thinking through what are the dangerous things and what are the various interactions. In a sense, a coverage model should be a map of your fears. And so if you are assuming that in this ODD there will be multiple car types, and there will be trucks, busses, and so on, then you had better define a coverage model that goes through them all. And if you think there will be snow and rain as well as nice days and fog, you had better go through all of these and then make sure that you cross them all and combine them all. And if you don’t have the assets, or if there’s a specific simulator you’re connected to that does not support snow, for instance, then you should do something about it, such as using a better simulator.
In your demo showing the test scores, ranks, etc., could you explain again what you are optimizing in terms of “ranks?”
Ranking is one of the optimization capabilities that Foretellix built on top of the OSC2 standard input format. Specifically, ranking optimization helps you create an optimized test suite for the entire V&V effort or for selected V&V needs.
The fact is that executed scenarios cover their own specified intent but might also cover much more in a by-the-way manner. For example, while doing a cut-in in a random location I may also drive under a bridge. Ranking can take a test suite with 500 tests and identify 50 tests that produce the same coverage result. In subsequent test regressions, I may run 50 scenarios that have minimal redundancy, shorten the test suite execution time, and save the expensive simulation cycles for other goals.
Can your tool be also used for parameter identification through its optimization capabilities? Is there a predefined workflow for that?
The answer is yes. Please note that these webinars are really about the approach. CDV efficiently spans the desired space and identifies unknown scenarios that can later be sent to a KPI optimizer. Specifically, Foretellix technology uses machine learning algorithms to identify feature importance, which can help both debug and efficient scenario exploration.
Do you consider the probability of scenarios when selecting them or when evaluating the performance of the AV in the report?
Yes. By default, unified distribution is applied for value selections – this means that all legal values have the same unbiased chance of being selected. You can use OSC2 default constraints to capture the desired probabilities for value selection. As the name suggests, default constraints apply default values. If a test constraint further steers the needed distribution (for example, for an edge case scenario), these constraints are ignored. Note that in edge case scenarios, even though one behavior was pushed to the extreme, it is important that other behaviors are normal to avoid a scenario that is just too crazy. Note that in some cases where statistical reports are needed, a joint distribution needs to be applied.
How do you define “undesirable” results such as a collision?
OSC2 provides success criteria mechanisms to enable self-checking tests. Such mechanisms are critical to enabling scale. Two main checker categories are:
- Generic checkers – Applied for every execution regardless of the executed scenarios (for example, don’t collide with other actors)
- Scenario specific checks – Applied for a specific narrow scenario context (for example, in the cut-in scenario end of change lane phase, allow a maximum of 1s TTC).
Are these sequences of behaviors open loop? e.g. in the lane overtaking sequence, could you randomly generate a sequence where the actor sideswipes the AV? How would you isolate those scenarios where a collision is due to an overly aggressive actor rather than the AV’s failure? Since you’re generating a huge volume of scenarios, manual triage isn’t an option.
This is exactly true. When you go from the thousands of runs per night to the hundred thousand runs per night, you can no longer think about manual checking of things. Not every accident and not every collision is necessarily a SUT error. If you create a challenging scenario where, for example, 50% of the instances of that scenario are supposed to end in a collision, then such collisions are not obviously all errors of the SUT. You need a pretty sophisticated way to define what is clearly an error, what is clearly okay, and what are the gray areas that you may want to check later? And it is a combination of technology, methodology, and even art.
You also need a standard format for errors, and you need tools that help you cluster the errors, help you analyze them. We didn’t get to show that, but I think that’s an interesting thing to see.

If the randomly picked parameters generate a combination that is not physically possible for a vehicle at runtime, how is it handled?
The constraints include both scenario constraints, such as vehicle category, and implied physical constraints, such as those that connect distance to speed, to acceleration, and so on. An OSC2 tool should adjust the scenario to meet both your scenario and implied physical constraints, or it should report an error if no such scenario can be achieved. Many times, the constraint solver may report constraint contradictions even before simulation starts. In the case of partially controlled actors (for example, smart actors driven by behavioral models) a runtime contradiction may be reported. As was said previously, Foretellix tools load the physical constraints by default, so users can focus on the abstract scenario constraints.
Is there an open parser/interpreter to validate a scenario?
One of the advantages of a standard is that the multiple vendors involved will push the industry forward. PMSF suggests a parser and CLI for OSC2.0 syntax checking. For more information, please click here.
How should we set the scenario parameter range?
Scenario parameter ranges are just another type of constraint. As was discussed, abstract scenarios can include any constraint kind to capture dependencies. A parameter range can be between any two expressions: not just a literally specified range such as keep(speed in [10.100]KPH) but also keep(speed in [attr_a..attr_b]). Note also that the final calculated values will be a resolution of the range and the context scenario. For example, if a truck is used as part of the cut-in scenario, the eventually randomized vehicle speeds will conform to both the range requirement and the truck speed capabilities.
Are the trajectories generated kinematically feasible by default? If not, is there a way to encode such constraints?
By default, generated scenarios and dynamics are both feasible and physically possible. Note that virtual platforms may benefit from running scenarios that are not physically possible. (For example, you can save simulation time by allowing infinite acceleration.) The OSC2 LRM and domain model allow executing actions that are not physically possible, as well as those that are. There are methodology guidelines on how to write reusable scenarios that are portable between virtual and physical platforms.
How do you create edge-case scenarios?
The definition of edge-case scenarios can be wide. It could be non-typical parameter values, the desired traffic density, error injections, road conditions, a specific mix of scenarios, and more. There are efficient ways to come up with the right set of edge-cases in the planning process. Once the plan is set, OSC2 facilitates translating the functional goals into abstract scenarios and a coverage model to efficiently meet these goals.
Is there a reference implementation for tools implementing the format?
Not at this point. In terms of effort, it would be extremely challenging to create a reference implementation. Also, past experience has shown that a reference implementation prevents industry progress by forcing a specific implementation scheme on vendors so that, for example, constraint solvers did not progress.
As usual, drive safe,
Sharon