Short on time? Below is a podcast summary of this blog, generated by Google NotebookLM. You can also download the full PDF version or keep reading below.
In this blog, I will look at the near-term future of AI-based autonomy and will discuss:
- Some trends in AI-based autonomy – E.g. the move to “end-to-end”
- The growing role of V&V in autonomy – And the need for a common tool for both V&V and implementation of AI-based systems
- How AI will help V&V – In sensor simulation, behavioral models, text-to-scenario, AI assistants etc.
- Why abstractions will always be needed for V&V – And how they should be expressed
Before moving on, let me clarify what I mean by “near-term”, “AI-based autonomy”, “abstractions” and “V&V”.
Please note that this is a blog, not a scientific paper, so kindly forgive some informality.
Definitions
“Near term”: The future is arriving a lot faster lately, so it is hard to be sure about the timeline. In this document, when I refer to “near term” I mean, say, the next five years (but I expect much of this to happen over the next two years).
“AI-based autonomy”: I use “autonomy” as short-hand for safety-critical, embodied (physical) autonomy: Autonomous (or semi-autonomous) vehicles, robots, ships, drones and so on. I’ll use Automated Driving Systems (ADS), and especially Autonomous Vehicles (AVs) as my running example, but the discussion applies to all of the above. Some of the observations probably apply to safety-critical non-embodied autonomy, but I’ll ignore that for now.
I use “AI-based autonomy” for the increasingly ML-based autonomy. It can refer to full end-to-end systems, or to AV architectures where ML is taking a key role (e.g. Compound AI Systems as discussed here).
“Abstractions”: By that I mean “formal abstractions” – the explicit and exact definitions or encoding of specific human knowledge, e.g. from the domains of mathematics, physics, and driving rules. For example, the notions of “time to collision” and “four-way stop” are formal abstractions.
There are also “informal abstractions” – I’ll talk about those separately, and explicitly use the term “informal abstractions”.
“V&V”: Verification and Validation normally refers to the process of gaining confidence in the safety/quality of the system, finding and fixing bugs, and so on. It is an iterative process which uses what I am calling below “data automation facilities”.
“Data automation”: I’ll use the term “data automation facilities” to describe the facilities (machinery, methodologies, content) used in V&V. This includes defining metrics (coverage space, KPIs and checks), generating / matching scenarios, evaluating metrics, handling requirements, triaging, fixing the bugs and so on.
The reason I am calling them “data automation facilities” (rather than just “V&V facilities) is that these facilities turn out to be extremely useful not just for V&V, but also for the implementation process (e.g. to guide ML training), as we’ll see below.
Expected trends in autonomy
Here are some trends I expect over the next few years (details later):
- Autonomy will be increasingly AI-based
- Whether it will be fully end-to-end, or just more-ML-based, is unclear
- The autonomy market will quickly grow
- E.g. people are already working on generic, multi-task, foundation-model-based robotics frameworks (here is one)
- The effort to deploy autonomy will be increasingly about data automation
- AI will also play an increasing part in doing data automation
- But data automation also needs transparency and abstractions
At any given time, autonomy builders will look for the most efficient way to achieve the desired level of safety. This will involve the right mix (for that time) of AI in the implementation, AI in the data automation, and non-AI pieces.
The growing role of data automation in AI-based autonomy
Much of system development is about V&V: There is an old joke saying that all system development is about V&V: You simply start with an empty system, and V&V discovers the “nothing works” bug.
How does that change when we move to safety-critical AI-based autonomy? I claim that data automation (of the kind used in V&V) is much more important in that world, because: AI makes it easier to construct complex systems, but they are often buggy (consider LLM hallucinations), and they are harder to verify (because they are mostly black-box). So the “V&V ratio” (the ratio of time spent on V&V vs. implementation) keeps growing.
But also, the implementation process itself needs data automation facilities. I’ll discuss this more below, but the short version is as follows: Designing AI-based autonomy is mostly about ML training. And to train the system correctly on the “full space of things it may encounter” you have to explore that space, and also codify what are “good” and “bad” behaviors in the space. This sounds a lot like coverage and checking.
Also, bug fixes / feature additions are mostly about adding (corrective and negative) examples to the training set. And all that exploring, finding bug examples and so on needs more-or-less the same V&V facilities (which we now call data automation facilities). Note that the AI training world uses the term “data flywheel” for much of this.
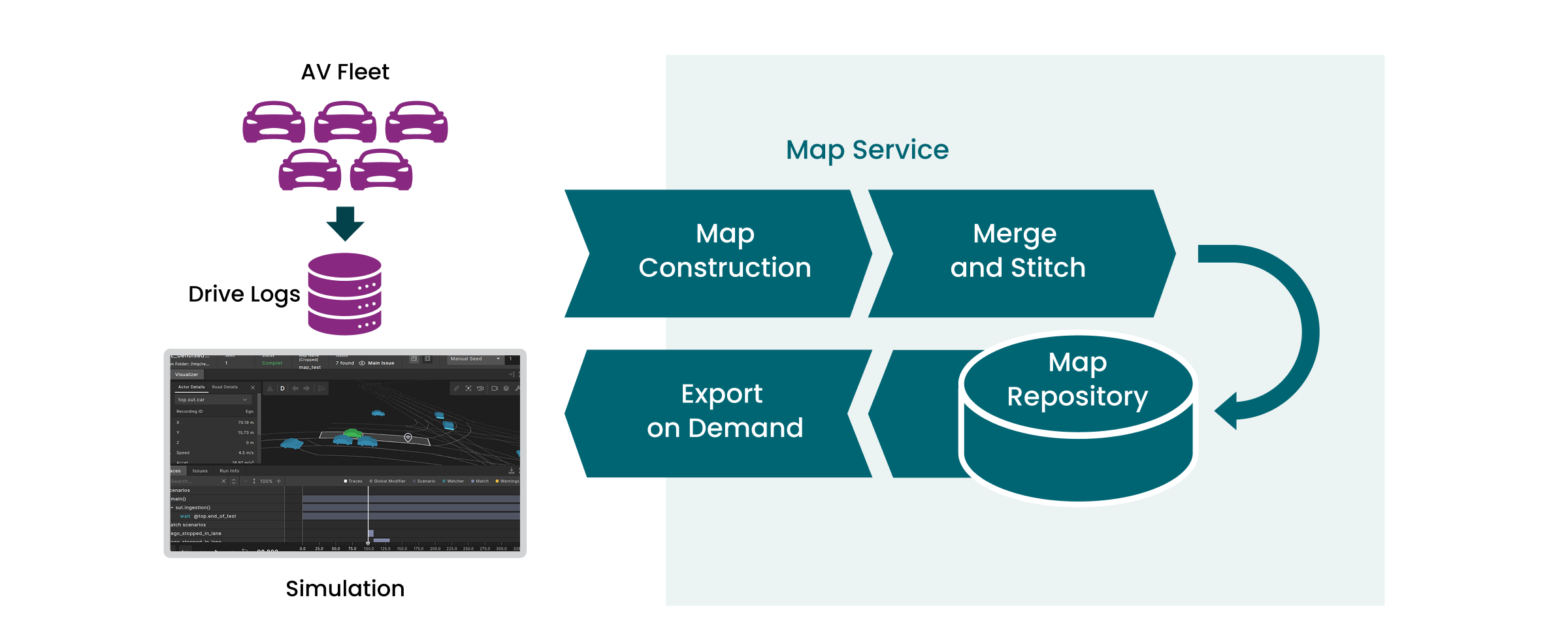
Perhaps it is no exaggeration to say that the majority of the effort of building and deploying such systems is about data automation. See below a high-level picture demonstrating that.
Data-Automation for AI-Centric AVs

Using data automation in the implementation process
Let’s use an end-to-end AV as our example. A huge part of making it work (and then making it safe enough) is about training the ML system. This involves data automation in two ways:
- Use data automation to enumerate the various “areas” and train on examples of them
- Use data automation to find bugs in the “current system”, then fix them via further training
Let me start with the second part (though it often happens later). This is really an extension of the “normal” V&V process:
- Take the current trained system
- Do very good V&V
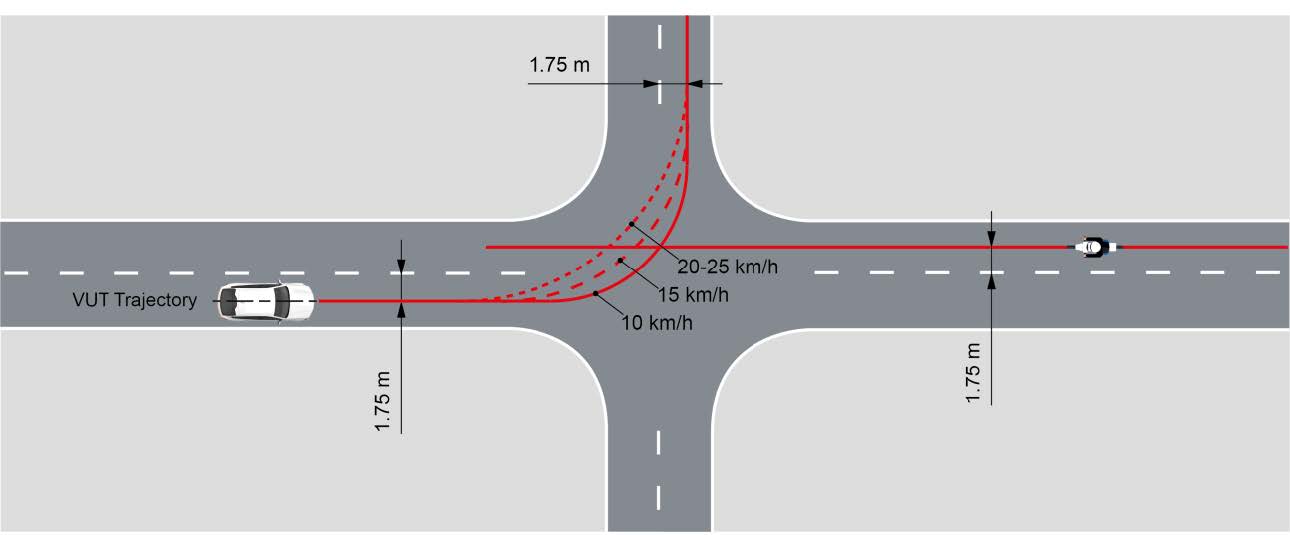
- Ideally use a detailed “verification plan” (VPlan) which is appropriate for the Operational Design Domain (ODD)
- Fill coverage using real-world drive log evaluation and synthetic test generation
- Do checking, failure triage and so on
- Whenever you find a bug
- Generalize it to “the problem area”
- Find / create enough examples for that area
- Use them to “fix” the training set (using corrective or negative feedback)
- Loop until the targets (safety, legality, comfort etc.) are reached
But we also need the first part – the second part is not efficient enough: It takes a lot of V&V effort to encounter the bugs. It is more efficient to train on the various areas even before finding any specific bugs:
- Enumerate the “areas” you can think of (including “difficult areas”)
- E.g. “handle various other-actor illegal behavior”
- Create a detailed VPlan accordingly
- Create “enough” examples for the various areas
- Using real-world drive log evaluation and synthetic test generation
- Train on them
In reality, people will use both techniques iteratively, and both need more-or-less the same data automation facilities, and we’ll see below.
V&V and implementation need similar data automation facilities
So we need similar data automation facilities (machinery, methodologies, content) for both purposes. Here are some examples of that:
- Finding examples in real world drive logs
- Required for both V&V and training (where it is part of the curation process)
- Enabled by data automation scenario matching
- Augmenting real world drive logs to improve the coverage
- Required for both V&V and training
- Enabled by data automation smart replay of real-world drive snippets (+ variations)
- Creating fully synthetic scenarios for safety critical, very rare areas
- Required for both V&V and training
- Enabled by data automation constrained random generation based on abstract scenarios
- Using a formal abstraction language to capture scenario definitions, coverage goals, KPI etc.
- Required for both V&V and training (see below)
- Enabled by using a standard, Domain Specific Language (DSL) for abstract (evaluation and generation) scenario definitions – OpenScenario DSL
- Doing triage and debug
The growing role of AI in data automation
AI-based autonomy depends on doing data automation well, but luckily AI can offer significant help in the data automation process itself. This includes things like:
- AI-based improved sensor simulation
- Including neural reconstruction and similar techniques
- AI-based behavioral models
- Which exhibit more natural behavior
- AI-based text-to-scenario and text-to-matched-instances facilities
- Often based on Vision-Language foundation models
- AI-based V&V assistants
V&V assistants: I am particularly bullish about multi-modal, foundation-model-based “V&V assistants”, which can access the computer and do a growing part of what a V&V engineer does. They will, of course, be wrong sometimes. But for any set of tasks where they are (say) “correct” in more than 80% of the cases, they will become extremely useful.
Consider a triage-and-analysis assistant: It runs in parallel to (say) the nightly multi-test execution flow, stops/corrects erratic simulation runs, does triage on its own and so on. But because it may sometimes be wrong, it is crucial that:
- The assistant will leave a detailed, structured log of what it did (and why)
- You should be able to chat with it about any detail in the log
- The assistant’s “decisions” (e.g. failures clustering and categorization) will be “undo-able” (e.g. stored in Git so you can revert/modify them)
Over time, AI assistants will improve: They will be able to auto-create tests (e.g. to try and expose more instances of a suspected bug), and much more. Which raises the following question:
Can all V&V be done by AI?
The short answer is “no”: People are not going to be satisfied with the answer “The AI said it’s OK”. About 7 years ago, I wrote a blog post about a similar topic, and claimed that:
Regulators (and common sense) will insist that verification will be based upon human-supplied requirements, consisting of scenarios, coverage definitions, checks and so on – let’s call them all “rules” for short. So some rule-based specifications will always be here.
Much of this is about abstractions. The rest of this document will discuss in more detail why human-defined abstractions are essential for safe AI.
What do assessors need?
Both AI-based autonomy and AI-assisted V&V will arrive gradually: For instance, over time we’ll have better and better V&V assistants, but at any given time we’ll still need to somehow check that they did the right thing. So the work of V&V will always have some human part in it.
One good way to look at this is to start from the “assessors”: There will always be people whose job is to assess, in a very thorough way, whether the autonomous system is indeed trustworthy. “Assessing” here means making sure that:
- We tested all the “required situations” (“coverage”)
- We applied the right, context-dependent criteria to each situation (“checking”)
- The results were “good enough” to meet the target safety
Who are those assessors? I use this term in a fairly general way: There are various categories of humans who will be required to assess the autonomous system, including:
- Regulators
- The jury in an AV-related accident trial (those are not going to disappear)
- An AV fleet operator (before choosing a specific AV supplier)
- An OEM (before accepting an external AV stack)
- An AV company’s mgmt. team (before making a “deploy” decision)
- An AV company’s V&V team (before accepting a change)
- And so on
How is assessing done?
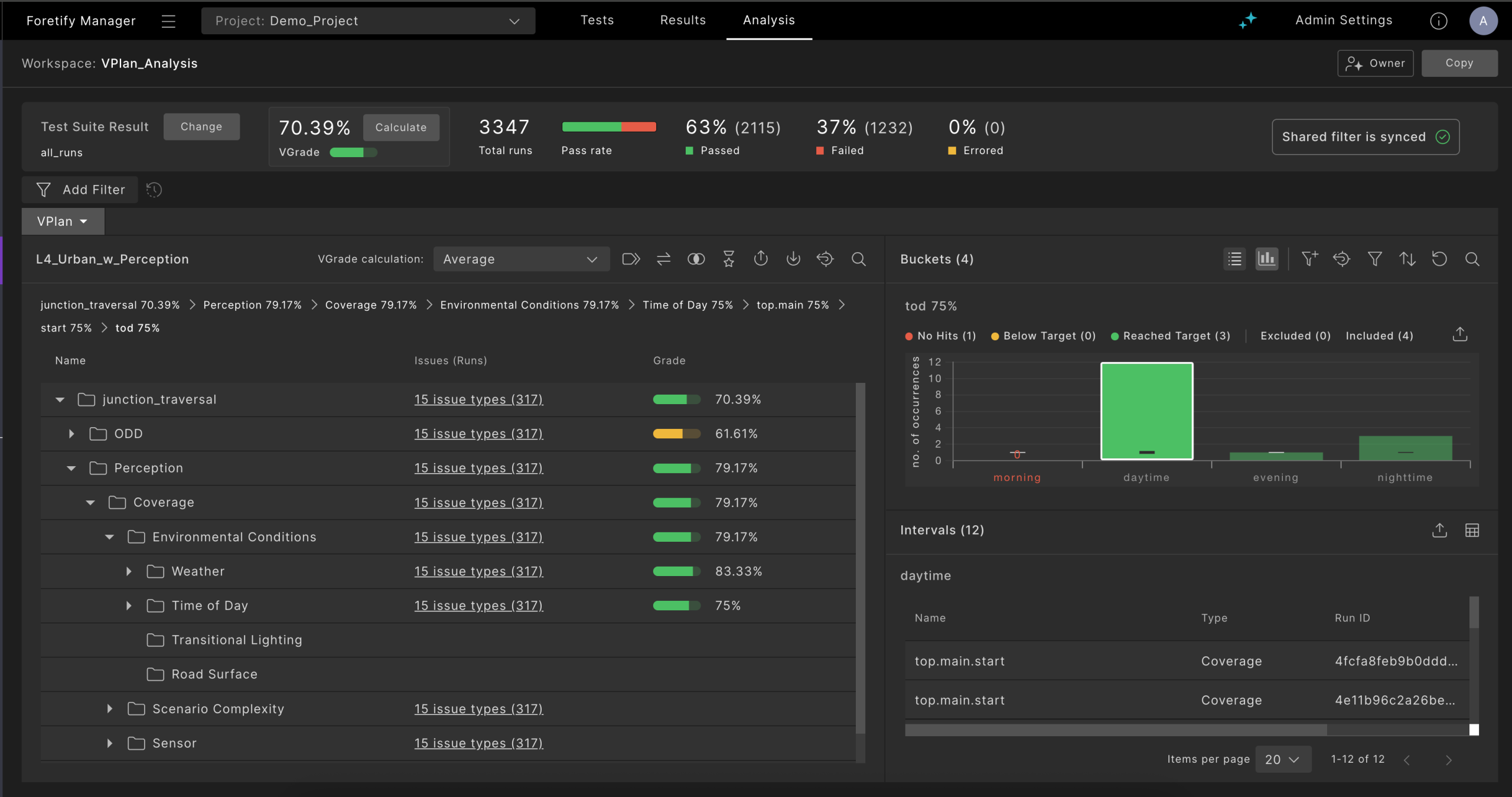
To do a good job, a reasonable starting point is a well-written safety case. And that safety case should (among other things) point at the various situations tested (coverage), the checking done, and the results.
The assessor should be able to dive into that information (safety case, verification plan / coverage results, checks / KPIs, triaged test results and so on) to any depth, to convince themselves that the implementation is now trustworthy (or to understand where it is not).
The assessor may use a V&V assistant (e.g. to understand what-was-tested at various levels of granularity). In fact, I expect this to be pretty helpful, perhaps using “debating assistants”, where one assistant tries to convince the assessor that the system is well-tested, and a second assistant looks for reasons why it is not.
But regardless of whether assessors are aided by human or AI assistants, eventually they need to convince themselves that a “reasonably comprehensive set” of the needed situations was covered and checked, and the results were “good enough”. And this implies transparency, human terminology and well-defined abstractions.
The role of abstractions
Assessing needs abstractions: You need precise (intuitive but formally-defined) terms for expressing the situations, checks and results. Terms like “time to collision”, “unprotected turn”, “rolling stop”, “left-driving-countries”, “minimal risk maneuver” and so on should be formal, precisely-defined abstractions.
Note that the actual end-to-end autonomous implementation is not limited to “thinking” in terms of these abstractions: This is actually a good thing for the implementation (allowing it to also handle vague cases). But you do need abstractions to assess the behavior (and for the implementation process, e.g. to influence training).
Also note that informal abstractions (e.g. AI-based text-to-scenario) are also very useful – more on this below. However, since they are not precisely-defined, they cannot replace the need for formal abstractions.
So abstractions will be crucial for V&V (and data automation in general). This will become clearer below, as I dive into the usage of abstractions in coverage and checking.
Coverage abstractions
Suppose you are starting to define a “coverage map” of your ODD (for either V&V or implementation, as discussed above). You need to consider maneuvers, weathers, faults and much else.
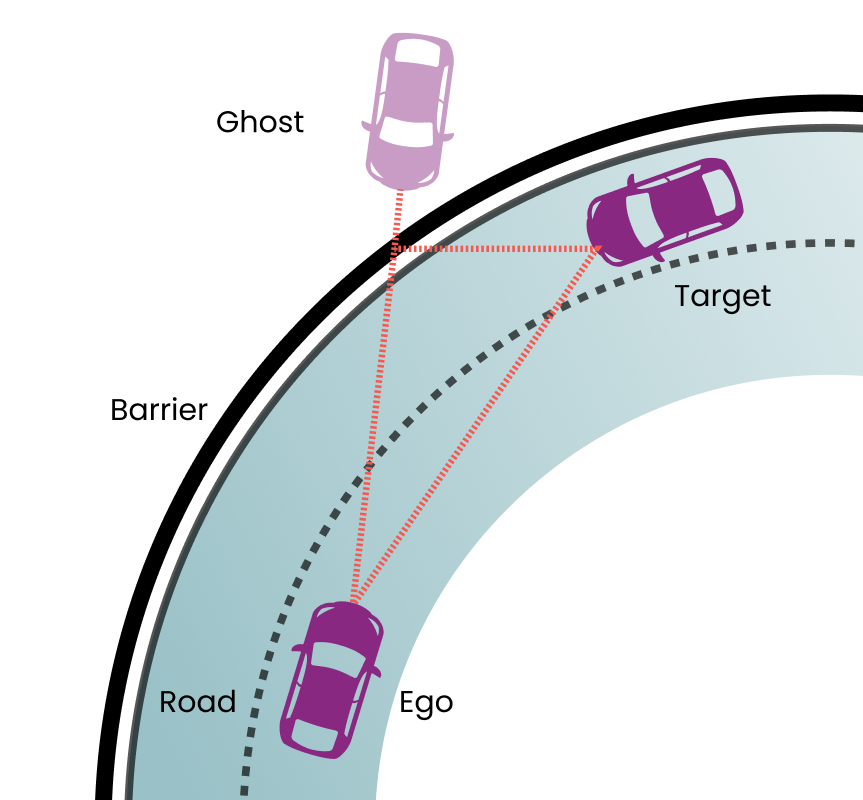
You then split e.g. the maneuvers space into scenarios (unprotected turns, four-way stops and so on). You then further split your scenarios into cases (coverage bins): Left and right unprotected turns, time from yellow light to start of crossing (split into specific time-range bins), speed of nearest vehicle when crossing (split into specific speed ranges), “close calls” where the Post Encroach Time (PET) was less than N seconds, and so on.
Note that these terms (“unprotected left turn”, “PET” etc.) are all abstractions which need to be precisely defined. And then you may want to combine (mix) each of these scenarios with other scenarios involving even more abstractions (“flat tire”, “sensors disabled”, “emergency vehicle enters junction”).
So you need some formal language to evaluate which of these scenarios happened, split them into bins according to which sub-cases happened, measure things like PET and so on. And this needs to be fully-transparent to avoid misinterpretations.
Checking and KPI abstractions
Checking is even more complicated, and needs even more abstractions:
- You need to compute various KPIs
- E.g. PET and time-to-collision
- You need to check for obeying rules and conventions
- Checking often depends on context
- E.g. don’t cross a solid dividing line, except if it must be done (e.g. to avoid a running pedestrian on the road)
- So you also need formal definitions for those “context scenarios”
- Checking is also country/ODD-dependent
- E.g. not all countries have four-way stops
- E.g. if you don’t support rain, you have to check how your vehicle does Minimal Risk Maneuver when it starts raining
And all these need to be defined transparently using formal abstractions.
Note that sometimes you need to combine this with “informal abstractions” (because some of the concepts are inherently vague). More on this below.
About finding unknowns: You may think that finding unknown unsafe situations (as per SOTIF) does not need abstractions – you don’t know what you are looking for, so you can’t express it abstractly.
But that’s not really the case. Looking for unknowns is best done as follows:
- Complement real-world log data by generating new data (especially for corner cases)
- While smartly mixing together known, abstract dimensions
- While randomizing various parameters
- Note that randomizing and still getting valid results requires abstractions – e.g. for creating an “unprotected left turn with PET < 3 seconds”
- Look for indications of something starting to go “bad” (e.g. low time-to-collision)
- This is also usually defined in abstract terms
- Then maybe use various data-driven search techniques to home in on the problem
- Thus turning it from unknown to known
The role of Informal abstractions
As I mentioned above, informal abstractions (especially multi-modal, foundation-model-based abstractions) can be extremely useful. The trick is when to use them, and how to combine them with formal abstractions.
One example is “text-to-generative-scenarios”: While it is hard to “direct” this precisely, it can still be very useful in many cases (to quickly-and-intuitively guide the generated scenario), as long as it is coupled with the ability to evaluate the results using formal abstractions.
Another example is “text-to-matched-instances”: Sometimes we do need instances of somewhat-vaguely-defined abstractions (“need to yield”, “be considerate to pedestrians” etc.), as part of our coverage and checking mechanisms.
There are complex situations where the “correct” behavior partially depends on informal abstractions. Often an abstraction has a clear, formal subset (for which a rule will give a simple answer), surrounded by a fuzzier, informal area (where the rule is less clear, and violating it should perhaps result in just a warning).
To summarize
These are the four key takeaways
- AI-based autonomy is advancing much faster now
- As a result, the relative importance of V&V is rising
- Data automation (for both implementation and V&V) is gaining importance
- Formal abstractions are a central part of that
Download the Blog
.soundRow {
display: flex;
justify-content: space-between;
align-items: center;
flex-direction: row;
}
body > div.elementor.elementor-17930.elementor-location-single.post-34606.post.type-post.status-draft.format-standard.hentry.category-cto-blog > section.elementor-section.elementor-top-section.elementor-element.elementor-element-efdd4be.elementor-reverse-mobile.elementor-section-boxed.elementor-section-height-default.elementor-section-height-default > div > div.elementor-column.elementor-col-66.elementor-top-column.elementor-element.elementor-element-05119b0 > div > div.elementor-element.elementor-element-55dda35.elementor-widget.elementor-widget-theme-post-content > div > div > div.soundCol > iframe {
min-height: 190px !important;
height:auto!important;
}
@media screen and (max-width: 768px){
.soundRow {
flex-direction: column;
}
}